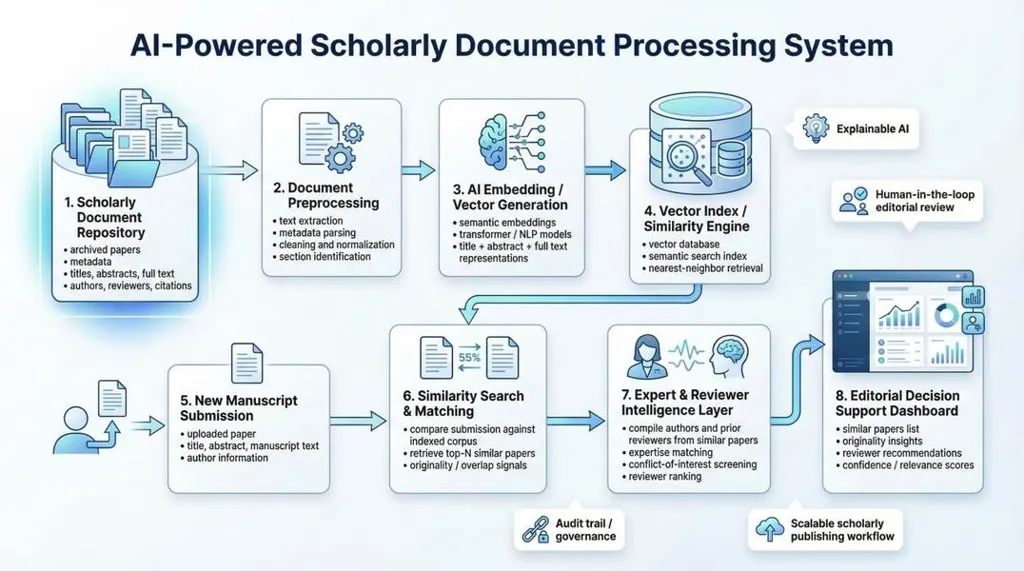
Scientific publishing is not a linear conveyor belt from submission to decision; it is a sequence of operational, high-stakes micro-decisions that have to meet policy, integrity, and governance requirements while still being fast enough to be useful to authors and readers. Every submission to a scientific journal is the opening gambit in a sequence of decisions and sub-decisions; intake triage, scope fit, editor assignment, reviewer matching, and integrity checks, where minor errors create a cascade of reroute and rework measured in weeks.
That's why the most impactful AI in publishing is not the kind that generates paragraphs. It's the less visible layer that reduces avoidable rework while preserving editorial judgment.
Founded in 1876 at New York University, the American Chemical Society (ACS) is one of the world's largest scientific societies by membership, with 155,000. ACS Publications operates as the publishing division and manages a portfolio of 90 peer-reviewed journals.
At the ACS, Jofia Jose Prakash, an Enterprise AI Architect, designs and delivers AI systems that make high-stakes editorial decisions faster, more consistent, and auditable. She and her team build agentic workflows that improve decision throughput without turning editorial judgment into a black box. Her work strengthens the infrastructure behind publishing, where bottlenecks accumulate and where trust is either won or lost.
Here are five leadership challenges that are common across scholarly publishing organizations of any size, and how enterprise AI can help with them in a way executives can defend to editors, authors and risk teams.
1. Speeding up decisions without weakening editorial standards
Leaders experience that tension immediately: authors demand faster outcomes, editors demand control and quality teams want consistency. The mistake is to view cycle time as a single metric you can push down. In reality, cycle time is the sum of many small decisions, and the biggest driver of delay is rework created by early misclassification.
Enterprise AI starts to improve the first mile by standardizing intake, triage and routing at scale. Using historical outcomes and journal scope patterns, it can flag the right path early and surface risk signals at the point of entry. The goal is not to auto-reject. The goal is to reduce avoidable back-and-forth so the editorial team is not discovering issues weeks later.
Operating model shift: Define "good routing" as fewer reroutes, fewer escalations caused by missing context and fewer appeals tied to preventable mismatches.
2. Expanding reviewer capacity while reducing reviewer fatigue
Reviewer availability is a capacity problem, not just a matching problem. Many teams still rely on personal networks or familiar names, which creates predictable outcomes: the same reviewers get asked repeatedly, fatigue rises and turnaround slows.
This risk is explicitly called out in work behind AI-assisted reviewer recommendation, noting that repeatedly returning to known reliable reviewers can exhaust willingness to contribute, and that finding new reviewers without a pipeline becomes time-consuming and unreliable.
AI helps by building a broader candidate pool from prior publications and related work, then presenting ranked suggestions that editors can accept, adjust or override. It can also support similarity search to surface related papers, which improves reviewer selection and strengthens originality checks without forcing editors to invent the perfect search terms.
Operating model shift: Treat reviewer capacity as a managed resource. Track concentration risk, response rates, turnaround time and "reviewer reuse" across the portfolio.
3. Editor assignment depends on governance and capacity, not only expertise
Assigning an editor is not a simple expertise lookup. It must respect conflict-of-interest constraints, workload balance, and governance rules while still landing the submission with the right subject fit. When this stays manual, a few highly trusted editors get overloaded, queues become uneven, and decisions slow.
Jofia and her team tackled this by redesigning editor assignment as a constraint-driven matching system. The system treats COI exclusions and workload limits as hard constraints, then ranks candidates by subject fit and queue health. Jofia also introduced a tiered agentic workflow so automation matches risk: routine assignments run through lightweight rules and models; moderate-confidence cases trigger richer recommendations with stronger justification; low-confidence or constraint-breaking cases escalate immediately to human decision makers.
Each recommendation is packaged with an explanation; when no candidate meets constraints, the system escalates rather than forcing a weak assignment. This aligns speed with governance instead of trading one for the other, and it reduces downstream reversals because the decision is defensible from the start.
Operating model shift: Publish decision rules in plain language; plus require justification artifacts so editors can trust the recommendation and auditors can trace it.
4. Maintaining integrity and compliance at scale without building friction
Integrity checks are growing in scope: authorship signals, originality questions, paper mill indicators, disclosures and other compliance gates. Leaders often face a false choice: tighten checks and slow the system, or keep flow moving and accept higher risk.
AI can reduce that tradeoff by front-loading signals and prioritizing human attention. Instead of treating integrity as a single gate at the end, AI can continuously score risk across the workflow and route only the right cases into deeper review. This is where similarity detection and originality evaluation become operational tools, not afterthoughts. The reviewer-recommender work explicitly points to the need for better ways to evaluate originality beyond conventional search or personal knowledge.
Leadership move: Shift from "more checks" to "smarter checks." Measure false positives that waste time, plus false negatives that create reputational risk.
5. Reducing author churn by improving transfer paths across a portfolio
For multi-journal publishers, rejection is not the end of the relationship. It is a moment where customer experience and portfolio strategy intersect. Manuscripts rejected from one journal may be better suited elsewhere within the same publisher, but the transfer path is often inconsistent, manual and dependent on editor familiarity.
The business impact is real: research behind AI-assisted transfer explicitly notes that most rejected manuscripts are eventually published, but are less frequently published in journals belonging to the same publisher that initially rejected them. It also notes that authors receiving a reject-with-transfer decision are less dissatisfied than authors rejected without a transfer offer.
Enterprise AI improves this by making transfer recommendations systematic and defensible. The approach here is to convert structured text documents into vectors[numerical embeddings] and use a trained model to identify an appropriate journal for publication. The leadership value is not the model itself. It is the consistency it creates across the portfolio so authors get clearer next steps and editors are not improvising transfers under time pressure.
Leadership move: Treat transfers as retention. Track transfer acceptance, time-to-redirect, plus downstream outcomes like speed-to-publication and author repeat submissions.
What leaders should take away
Scholarly publishing runs on a trust-sensitive decision pipeline. The fastest way to modernize it is to improve the decisions that create rework: misroutes, late compliance gaps, stalled reviewer recruitment, and uneven editor load. The strongest AI programs treat these as enterprise operating problems, not tooling experiments.
Leaders should push for four outcomes:
- If your AI effort is not reducing reroutes, stabilizing workload, and increasing transparency, it is not improving the operating system. It is just adding another layer.
Outlook
The next competitive advantage in scholarly publishing will come from operational reliability, not model novelty. As submissions increase, reviewer supply stays constrained, and integrity expectations rise, publishers will be forced to industrialize triage, routing, matching, and compliance. Peer review will remain human-led, but the surrounding workflow will become more disciplined: clearer guardrails, faster escalation,
better visibility into bottlenecks,
stronger audit readiness.
The publishers that build this decision infrastructure will reduce delays and improve transparency for authors. Those that do not will face longer cycle times,
higher editorial load,
more author churn toward platforms that feel simpler and more predictable.
FAQ
Why start with intake and routing rather than peer review?
Because that's where rework accumulates. Fixing policy readiness and scope misroutes early reduces delays across the whole pipeline.
When is an agentic workflow appropriate?
Agentic workflows shine in bounded loops like triage, editor matching, reviewer recruitment or integrity triage where steps are well defined and escalation paths are clear. They shouldn't be used for final editorial decisions.
How can leaders measure success without publishing confidential metrics?
Track the number of reroutes, late policy failures, reassignments declines in reviewer recruitment stability of appeals overrides. Even without exact figures trends show whether friction falling trust holding.